ELI5: tf idf
// explanation
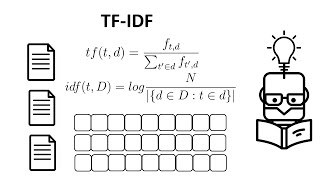
What is TF-IDF?
TF-IDF is a way to figure out which words are most important in a document [1][5]. Imagine you're reading 100 books and want to find which book talks the most about a special topic—TF-IDF helps you find the words that show up a lot in that book but hardly ever in the other books [4].
Why does it work?
The trick is that some words like "the" or "and" show up in every book, so they're not special [1]. But if a word appears many times in one book and almost never in others, that word is probably really important for understanding what that book is about [4][5].
How do computers use it?
Computers turn words into numbers using TF-IDF, so they can compare documents and find which ones are similar [2][3]. It's like giving each word a score that shows how meaningful it is.
Where is it helpful?
People use TF-IDF to make search engines work, organize documents, and help computers understand what text is really talking about [2][5].
// sources
Definition · The tf–idf is the product of two statistics, term frequency and inverse document frequency. There are various ways for determining the exact values ...
Dec 17, 2025 ... TF-IDF (Term Frequency–Inverse Document Frequency) is a statistical method used in natural language processing and information retrieval to ...
Convert a collection of raw documents to a matrix of TF-IDF features. Equivalent to CountVectorizer followed by TfidfTransformer.
Jun 4, 2020 ... The idea of the algorithm is that the most important terms have a frequency inversely proportional to document frequency (ie, TF-IDF).
Feb 3, 2024 ... TF-IDF is a numerical statistic that reflects the significance of a word within a document relative to a collection of documents, known as a corpus.
Video by Hex

Video by Krish Naik

Video by DataMListic